# 词典关系自动对照
**Repository Path**: rpa1/DataComparison
## Basic Information
- **Project Name**: 词典关系自动对照
- **Description**: 词典对照工具,利用Simhash相似度算法、stanford parser语义分析,使用机器学习技术可以记忆历史数据对照关系,实现词典库之间的自动、手动对照,不断完善数据模型。首先可以使用自动对照,如果自动匹配不精确,可以人工手动调整;
- **Primary Language**: C#
- **License**: GPL-3.0
- **Default Branch**: master
- **Homepage**: None
- **GVP Project**: No
## Statistics
- **Stars**: 0
- **Forks**: 1
- **Created**: 2021-03-01
- **Last Updated**: 2021-03-01
## Categories & Tags
**Categories**: Uncategorized
**Tags**: None
## README
# 词典关系自动对照-语义分析
#### 介绍
本工具只提供交流学习使用,可以免费使用,其中应用到的第三方控件库属于学习及可行性Deom验证使用,如果商业用途此控件请联系控件厂商购买版权。对使用过程中出现的任何问题不承担任何责任,本工具禁止商业用途,特此声明。本小程序最新本已经有多家公司用于实际生产应用中,当然是免费授权使用的,小工具而已,哈哈。
stanford parser是stanford nlp小组提供的一系列工具之一,能够用来完成语法分析任务。支持英文、中文、德文、法文、阿拉伯文等多种语言。在最新版本中相似度分析中应用了stanford parser语义分析,本人最近在研究汉语语法,发现挺有意思,学了十几年的英文语法,想不到现在需要开始研究自己的母语语法。对NLP有兴趣的可以联系交流。
stanford parser语义分析C#代码片段演示:
var jarRoot = @"..\..\models\lexparser\";
lp = LexicalizedParser.loadModel(jarRoot + @"chinesePCFG.ser.gz");
string yunWord= "主干识别可以提高检索系统的智能";
List keyWords= PanGuLuceneHelper.instance.Token(yunWord).Split('|').ToList();
var rawWords = SentenceUtils.toCoreLabelList(keyWords.ToArray());
var tree = lp.apply(rawWords);
tree.pennPrint();
ChineseTreebankLanguagePack tlp = new ChineseTreebankLanguagePack();
GrammaticalStructureFactory gsf = tlp.grammaticalStructureFactory();
ChineseGrammaticalStructure gs = new ChineseGrammaticalStructure(tree);
var tdl = gs.typedDependenciesCollapsed().toArray();
语义分析截图:
获取句子主谓宾,以及部分宾语补足语。
 可以实现词典库之间的自动、手动对照。可以自动通过语义算法计算两个词组的相似度进行自动匹配,如果自动匹配不精确,可以人工手动调整;除了相似度匹配外,还提供了历史词典库对照关系参考,所以伴随历史数据的积累,工具具有自我学习能力,提供自动匹配的精度。
配置手册
1、db文件夹放在C盘跟目录下,是数据库存储文件,数据库为Sqlite文件型数据库。
2、如果没有安装.NET Framework 4.6.1或以上版本,请下在安装.NET Framework 4.6.1或更高版本,安装方式请参考微软官方网站。
3、本工具为绿色免安装版,直接双击DataComparison.exe即可使用。
4、模板文件夹下是导入数据使用的模板格式,标准模板导入标准词典库数据,第三方模板导入第三方词典库使用。
使用手册
可以实现词典库之间的自动、手动对照。可以自动通过语义算法计算两个词组的相似度进行自动匹配,如果自动匹配不精确,可以人工手动调整;除了相似度匹配外,还提供了历史词典库对照关系参考,所以伴随历史数据的积累,工具具有自我学习能力,提供自动匹配的精度。
配置手册
1、db文件夹放在C盘跟目录下,是数据库存储文件,数据库为Sqlite文件型数据库。
2、如果没有安装.NET Framework 4.6.1或以上版本,请下在安装.NET Framework 4.6.1或更高版本,安装方式请参考微软官方网站。
3、本工具为绿色免安装版,直接双击DataComparison.exe即可使用。
4、模板文件夹下是导入数据使用的模板格式,标准模板导入标准词典库数据,第三方模板导入第三方词典库使用。
使用手册
自动匹配:

手动匹配:
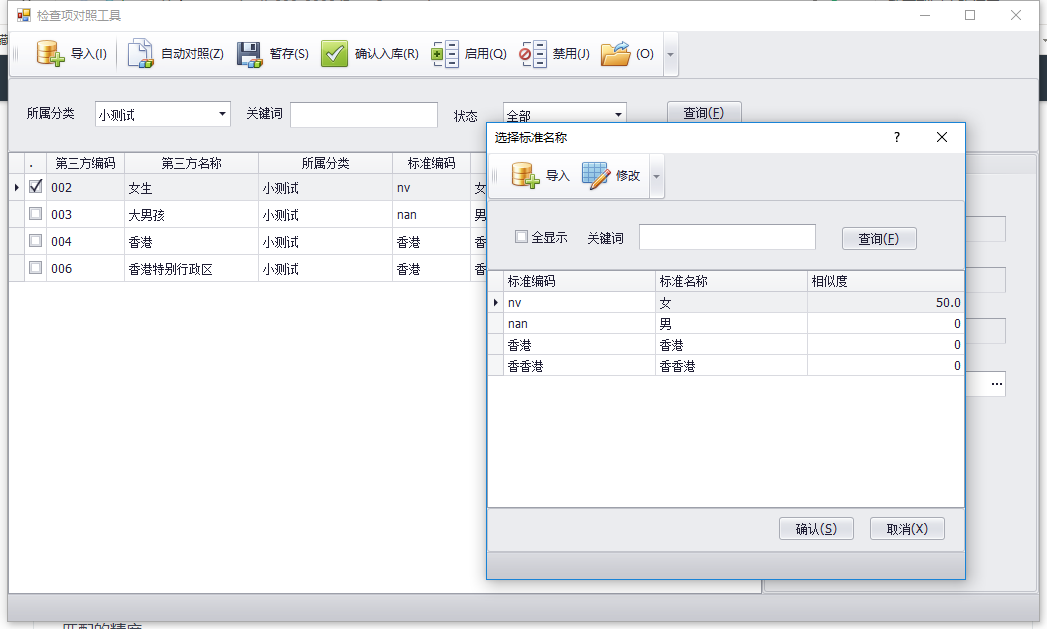 1、首先导入标准词典库。
2、后期可以不断导入第三方词典库,导入后显示“未对照”状态。可以利用自动对照功能,实现语义层的词典项对应关系的自动关联,如果匹配不对,可以手动再次对照词典项之间的关系。
3、对照完成,可以使用“暂存”功能,暂存词典项对照关系数据。状态变为“已对照”。
4、审核已对照数据无误后,可以实现词典项入库操作,变为“已入库”状态。
5、对照完成已入库的数据,只可以进行“禁用”与"启用"操作。
6、“导出”功能可以导出数据。
7、可以通过所属分类对第三方词典项实现分类。
8、标准词典修改维护功能待开发。
详细使用手册后期维护。各位如果对此小工具有需求、建议欢迎留言。
QQ:2065766212
1、首先导入标准词典库。
2、后期可以不断导入第三方词典库,导入后显示“未对照”状态。可以利用自动对照功能,实现语义层的词典项对应关系的自动关联,如果匹配不对,可以手动再次对照词典项之间的关系。
3、对照完成,可以使用“暂存”功能,暂存词典项对照关系数据。状态变为“已对照”。
4、审核已对照数据无误后,可以实现词典项入库操作,变为“已入库”状态。
5、对照完成已入库的数据,只可以进行“禁用”与"启用"操作。
6、“导出”功能可以导出数据。
7、可以通过所属分类对第三方词典项实现分类。
8、标准词典修改维护功能待开发。
详细使用手册后期维护。各位如果对此小工具有需求、建议欢迎留言。
QQ:2065766212