[arxiv] · [amazon.science blog] · [5min-video] · [talk@RIKEN] · [openreview]
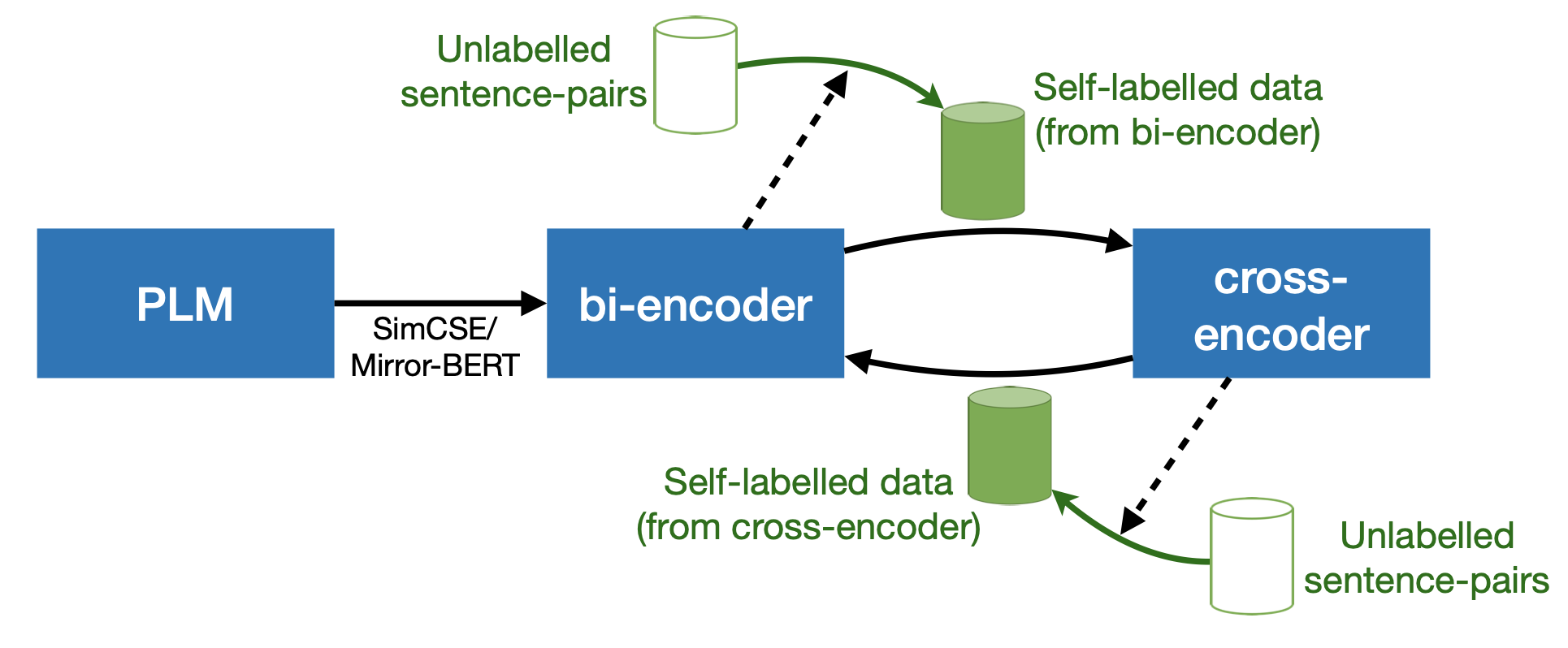 Code repo for **ICLR 2022** paper **_[Trans-Encoder: Unsupervised sentence-pair modelling through self- and mutual-distillations](https://arxiv.org/abs/2109.13059)_**
Code repo for **ICLR 2022** paper **_[Trans-Encoder: Unsupervised sentence-pair modelling through self- and mutual-distillations](https://arxiv.org/abs/2109.13059)_** | base models | large models |
|---|---|
| |model | STS avg. | |--------|--------| |baseline: [unsup-simcse-bert-base](https://huggingface.co/princeton-nlp/unsup-simcse-bert-base-uncased) | 76.21 | | [trans-encoder-bi-simcse-bert-base](https://huggingface.co/cambridgeltl/trans-encoder-bi-simcse-bert-base) | 80.41 | | [trans-encoder-cross-simcse-bert-base](https://huggingface.co/cambridgeltl/trans-encoder-cross-simcse-bert-base) | 79.90 | |baseline: [unsup-simcse-roberta-base](https://huggingface.co/princeton-nlp/unsup-simcse-roberta-base) | 76.10 | | [trans-encoder-bi-simcse-roberta-base](https://huggingface.co/cambridgeltl/trans-encoder-bi-simcse-roberta-base) | 80.47 | | [trans-encoder-cross-simcse-roberta-base](https://huggingface.co/cambridgeltl/trans-encoder-cross-simcse-roberta-base) | **81.15** | | |model | STS avg. | |--------|--------| |baseline: [unsup-simcse-bert-large](https://huggingface.co/princeton-nlp/unsup-simcse-bert-large-uncased) | 78.42 | | [trans-encoder-bi-simcse-bert-large](https://huggingface.co/cambridgeltl/trans-encoder-bi-simcse-bert-large) | 82.65 | | [trans-encoder-cross-simcse-bert-large](https://huggingface.co/cambridgeltl/trans-encoder-cross-simcse-bert-large) | 82.52 | |baseline: [unsup-simcse-roberta-large](https://huggingface.co/princeton-nlp/unsup-simcse-roberta-large) | 78.92 | | [trans-encoder-bi-simcse-roberta-large](https://huggingface.co/cambridgeltl/trans-encoder-bi-simcse-roberta-large) | **82.93** | | [trans-encoder-cross-simcse-roberta-large](https://huggingface.co/cambridgeltl/trans-encoder-cross-simcse-roberta-large) | **82.93** | |