# python-LDA
**Repository Path**: hren0315/python-LDA
## Basic Information
- **Project Name**: python-LDA
- **Description**: No description available
- **Primary Language**: Python
- **License**: Not specified
- **Default Branch**: main
- **Homepage**: None
- **GVP Project**: No
## Statistics
- **Stars**: 0
- **Forks**: 1
- **Created**: 2022-04-15
- **Last Updated**: 2023-11-19
## Categories & Tags
**Categories**: Uncategorized
**Tags**: None
## README
# python-LDA训练数据实现可视化
## 一、准备
- 实验环境:
python3.7
PyCharm Community Edition 2019.3.3 x64
- 实验数据:
上面给出的 舆情语料.zip可自行下载(也可使用自己的数据)
以及分词所需的停用词 stopwords.txt
## 二、整合数据
下载好语料后会发现有两个文件夹,train是训练数据 test是测试数据
每个文件夹中都有八个主题的小文件夹
每个小文件夹中又有许多.txt文本,其中训练文件中有40个,测试文件中有10个
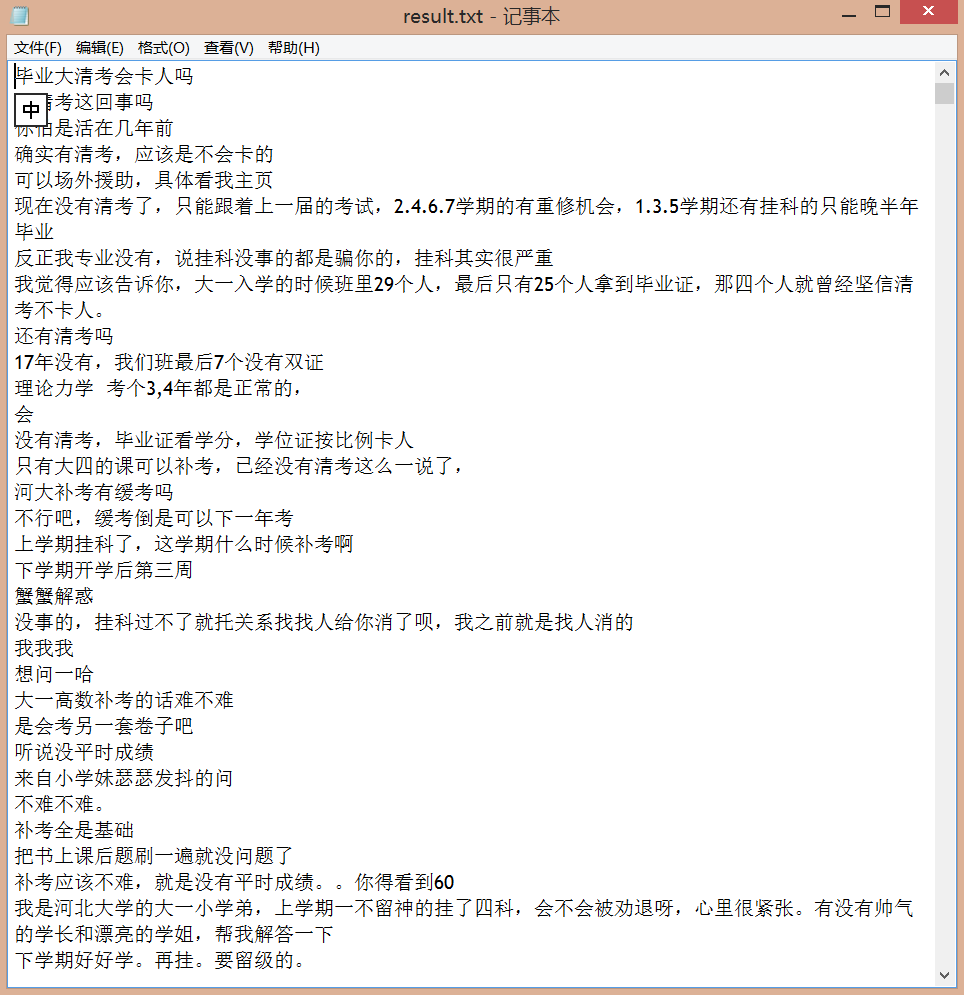
整合数据的目的就是将所有.txt文件整合到一个文本中备用
所用代码为 1-zhengh.py
注意修改文件路径!

整合好的文本都存到了result.txt文件中,如图
## 三、分词
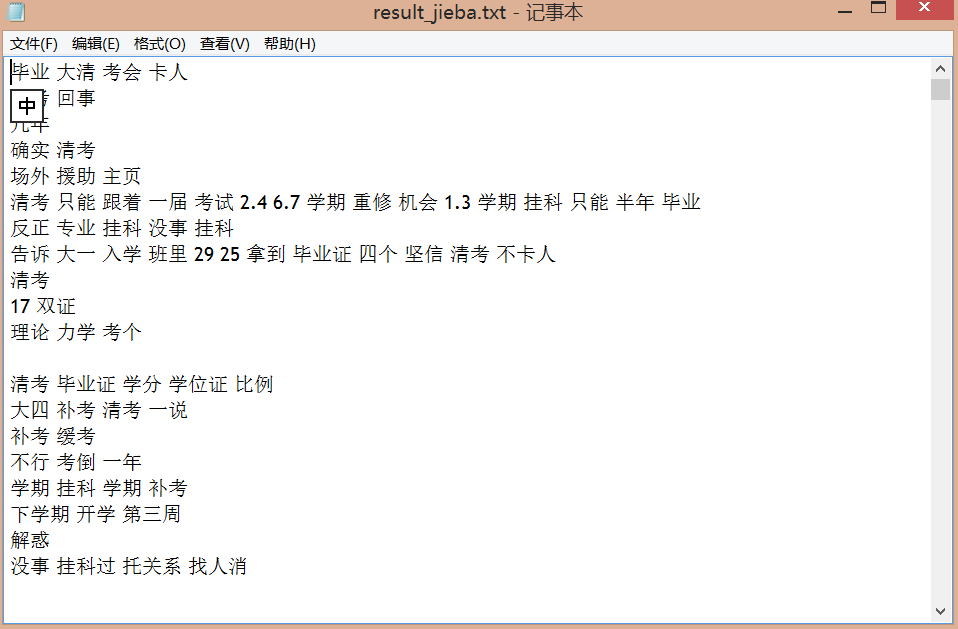
所用代码为 2-fenci.py
这里用到了停用词stopword(还是注意修改文件路径!)

结果如下,已经将一些对主题无帮助词语的去掉
## 四、词云制作
注:这一步与本项目无关,是我自己临时加的,可做可不做
所用代码为 3-ciyun.py
将分好词的文件制作成词云,背景图片可自己找,无关所谓,我做出来的是这种效果
## 五、训练模型及可视化
所用代码为 4-lda.py
此数据共4084个文档,主题词共690个
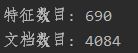
训练的主题个数共8个,具体如图所示

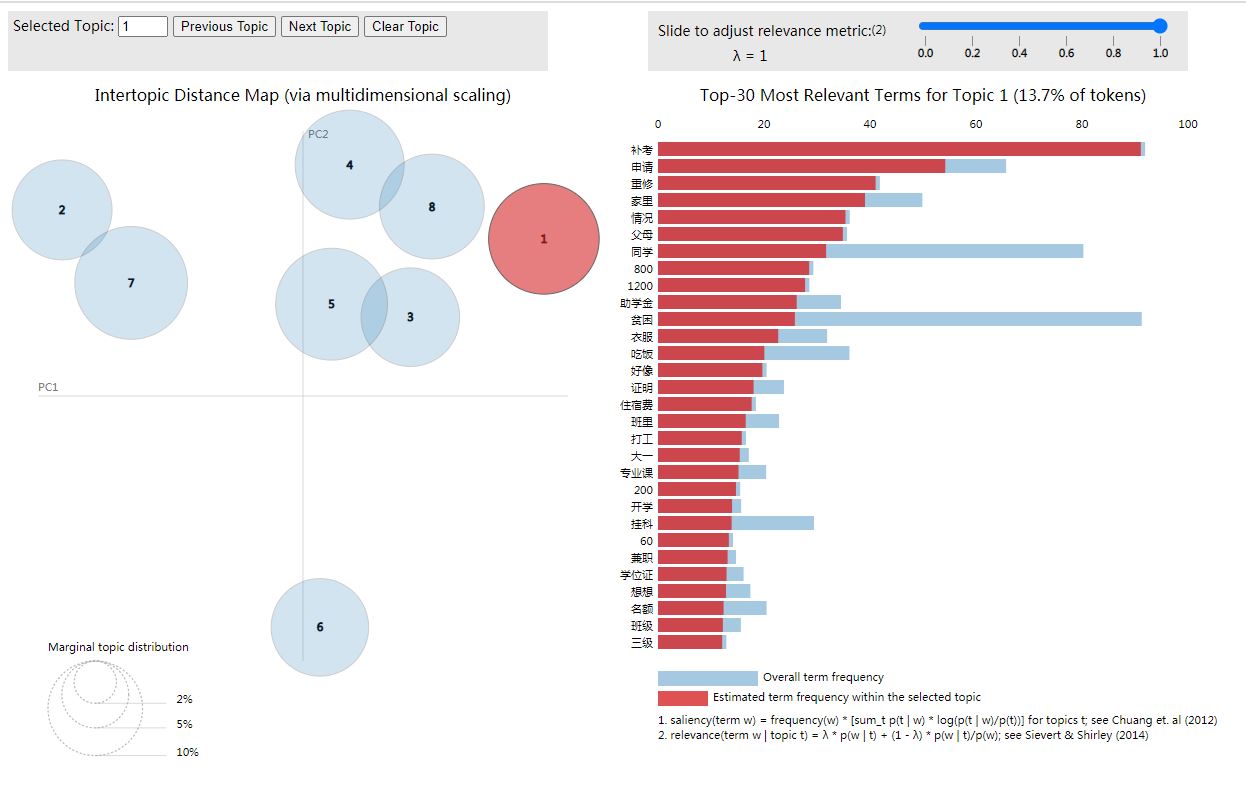
数据可视化
图中圆圈代表不同的主题,圆圈的大小代表主题的重要程度,圆圈越大表示该主题对应数据来说更重要。
如果圆圈之间有相互重叠则说明它们所代表的主题有相似之处
此项目完成