# 爬虫项目5 账号封锁
**Repository Path**: cthousand/item-5
## Basic Information
- **Project Name**: 爬虫项目5 账号封锁
- **Description**: 网站常用的反爬手段还有账号封锁,同一个账号一段时间请求次数达到阈值,便会被封锁,利用接码平台可以实现多个账号的连续爬取。此外,如果事先准备好了大量账号,可以可以利用账号池完成软解账号反爬。
- **Primary Language**: Python
- **License**: Not specified
- **Default Branch**: master
- **Homepage**: None
- **GVP Project**: No
## Statistics
- **Stars**: 0
- **Forks**: 1
- **Created**: 2022-04-26
- **Last Updated**: 2023-05-15
## Categories & Tags
**Categories**: Uncategorized
**Tags**: None
## README
# 项目5.企查查(新帐号注册策略)
***
### 目标网址
1. https://www.qcc.com/ 企查查
查找指定公司的企业信息,约500家。
 ##
## 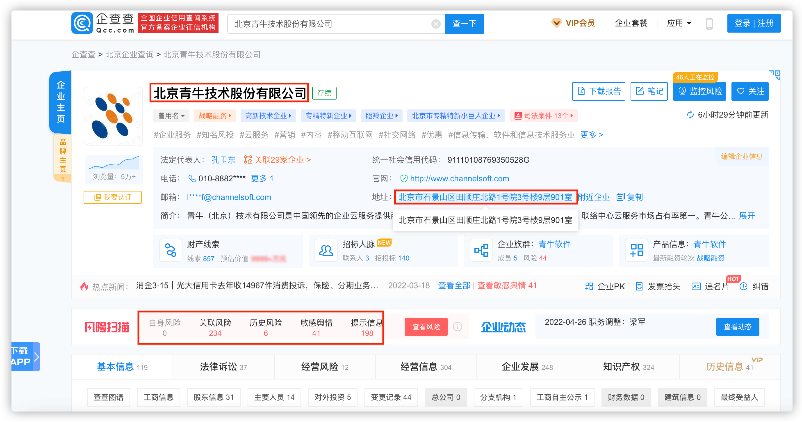
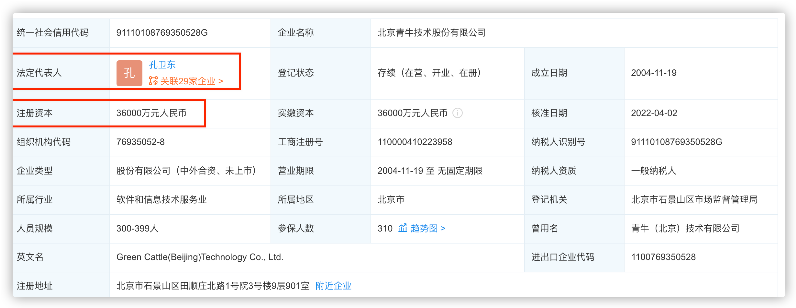 数据格式:[公司,注册资本,法人,自身风险数,关联风险数,历史风险数,敏感舆情,提示信息,省,市,区,详细地址]
## 方法分析
### 主要流程
1. 流程:selenium方法在首页搜索框中输入企业名称>点击搜索>拿到url>来到详情页面>解析html>数据保存。
2. 主要难点:
1. **登录验证窗口**:请求达到一定次数量后(约10次),会有登录验证窗口跳出。
- 解决思路:模拟登录,本项目用的是新账号注册登录(不用通过图像验证码校验)
2. **频繁请求窗口**:若同一账号多次访问后(约40次),会有频繁请求窗口跳出,要求我们进行验证登录(图形验证码的形式)。
- 解决思路:切换账号登录,如果继续用同一账号,即使通过了图像验证码,也会因为遇到账号异常被要求使用手机验证码登录,这里采用新账号登录则不会遇到。
3. 如何去找那么多的手机号?
- 一些第三方平台会提供这样的服务,如miyun,具体可以参考: https://zhuanlan.zhihu.com/p/438408532
这里用的是miyun,价格0.1元/个,充值最低5元。提供api接口。
### 脚本结构
数据格式:[公司,注册资本,法人,自身风险数,关联风险数,历史风险数,敏感舆情,提示信息,省,市,区,详细地址]
## 方法分析
### 主要流程
1. 流程:selenium方法在首页搜索框中输入企业名称>点击搜索>拿到url>来到详情页面>解析html>数据保存。
2. 主要难点:
1. **登录验证窗口**:请求达到一定次数量后(约10次),会有登录验证窗口跳出。
- 解决思路:模拟登录,本项目用的是新账号注册登录(不用通过图像验证码校验)
2. **频繁请求窗口**:若同一账号多次访问后(约40次),会有频繁请求窗口跳出,要求我们进行验证登录(图形验证码的形式)。
- 解决思路:切换账号登录,如果继续用同一账号,即使通过了图像验证码,也会因为遇到账号异常被要求使用手机验证码登录,这里采用新账号登录则不会遇到。
3. 如何去找那么多的手机号?
- 一些第三方平台会提供这样的服务,如miyun,具体可以参考: https://zhuanlan.zhihu.com/p/438408532
这里用的是miyun,价格0.1元/个,充值最低5元。提供api接口。
### 脚本结构
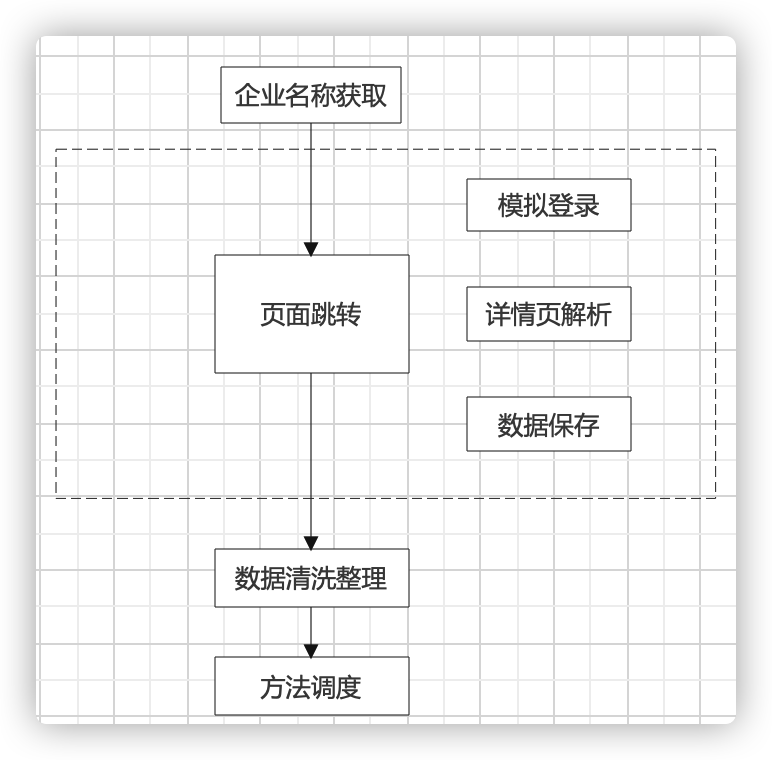 代码量200行左右,共建立了7个方法
1. 企业名称获取:从数据库中取出还没有完成爬取的企业名称(这要求事先将要爬去的企业名称存储在mysql数据库中,并新建一个保存表,取他们的差集)
2. 页面跳转:完成登录首页>寻找搜索框>填写企业名称>搜索>比较比较结果与目标的一致性>如果一致拿到企业详情页面的url>进入>将页面保存为html。这个方法中还引用3 4 5 方法。
3. 模拟登录:如果没有方法搜索框(说明出现了登录认证窗口),就执行,进入登录页面>填写手机号>发送验证码>填写验证码>登录的过程,其中手机号与验证码的获取调用miyun平台的api接口
4. 详情页解析:拿到html后,用xpath/css解析出所需要的数据,这里用的parsel模块
5. 数据保存:将数据插入到保存表中,并实现存在则替换,不存在则插入
6. 数据清洗整理:完成所有数据爬取工作后,将数据取出来用pannds等将其中的地址解析成省市区详细地址四级结构。
7. 方法调度:规定先执行什么,后执行什么。
## 代码实现
主体代码见同级目录下的py文件,命名方式是网页登录验证方式。
## 项目收获
Q1:mysql连接过程中,如果碰到连接断开的情况怎么办?
A1:在execute之前添加如下代码
```python
db.ping(reconnect=True) # 如果数据库没连上,就自动重连
cursor.execute(sql_save, data*2)
```
Q2:如何把一个地址变成省市区的格式?
A2:用cpca模块。
```python
import cpca
address="XXXX" #可以是字符串或series格式
df = cpca.transform(address) # 返回拆分好的dateframe对象
```
帐号池搭建见文件夹:帐号池
代码量200行左右,共建立了7个方法
1. 企业名称获取:从数据库中取出还没有完成爬取的企业名称(这要求事先将要爬去的企业名称存储在mysql数据库中,并新建一个保存表,取他们的差集)
2. 页面跳转:完成登录首页>寻找搜索框>填写企业名称>搜索>比较比较结果与目标的一致性>如果一致拿到企业详情页面的url>进入>将页面保存为html。这个方法中还引用3 4 5 方法。
3. 模拟登录:如果没有方法搜索框(说明出现了登录认证窗口),就执行,进入登录页面>填写手机号>发送验证码>填写验证码>登录的过程,其中手机号与验证码的获取调用miyun平台的api接口
4. 详情页解析:拿到html后,用xpath/css解析出所需要的数据,这里用的parsel模块
5. 数据保存:将数据插入到保存表中,并实现存在则替换,不存在则插入
6. 数据清洗整理:完成所有数据爬取工作后,将数据取出来用pannds等将其中的地址解析成省市区详细地址四级结构。
7. 方法调度:规定先执行什么,后执行什么。
## 代码实现
主体代码见同级目录下的py文件,命名方式是网页登录验证方式。
## 项目收获
Q1:mysql连接过程中,如果碰到连接断开的情况怎么办?
A1:在execute之前添加如下代码
```python
db.ping(reconnect=True) # 如果数据库没连上,就自动重连
cursor.execute(sql_save, data*2)
```
Q2:如何把一个地址变成省市区的格式?
A2:用cpca模块。
```python
import cpca
address="XXXX" #可以是字符串或series格式
df = cpca.transform(address) # 返回拆分好的dateframe对象
```
帐号池搭建见文件夹:帐号池