# PageIndex
**Repository Path**: ATM006/PageIndex
## Basic Information
- **Project Name**: PageIndex
- **Description**: No description available
- **Primary Language**: Unknown
- **License**: MIT
- **Default Branch**: main
- **Homepage**: None
- **GVP Project**: No
## Statistics
- **Stars**: 0
- **Forks**: 0
- **Created**: 2025-12-04
- **Last Updated**: 2025-12-04
## Categories & Tags
**Categories**: Uncategorized
**Tags**: None
## README


Reasoning-based RAG ◦ No Vector DB ◦ No Chunking ◦ Human-like Retrieval
---
📢 Recent Updates
**🚀 New Releases:**
- [🔥 **PageIndex Chat**](https://chat.pageindex.ai): The first human-like document analyst agent platform, designed for professional long documents (also available via the [API](https://docs.pageindex.ai/quickstart)).
- [**PageIndex MCP**](https://pageindex.ai/mcp): Bring PageIndex into Claude, Cursor, or any MCP-enabled agent. Chat with long PDFs in a reasoning-based, human-like way.
**🧪 Cookbooks:**
* [**Vectorless RAG notebook**](https://github.com/VectifyAI/PageIndex/blob/main/cookbook/pageindex_RAG_simple.ipynb): A minimal, hands-on example of reasoning-based RAG using **PageIndex** — no vectors, no chunking, and human-like retrieval.
* [Vision-based Vectorless RAG notebook](https://github.com/VectifyAI/PageIndex/blob/main/cookbook/vision_RAG_pageindex.ipynb): Experience OCR-free document understanding through PageIndex’s visual retrieval workflow that retrieves and reasons directly over PDF page images.
**📜 Articles:**
* ⭐ [**The PageIndex Overview**](https://pageindex.ai/blog/pageindex-intro): Introduces the PageIndex framework — an *agentic, in-context* **tree index** that enables LLMs to perform **reasoning-based, human-like retrieval** over long documents, without vector DB or chunking.
* [Do We Still Need OCR?](https://pageindex.ai/blog/do-we-need-ocr): Explores how vision-based, reasoning-native RAG challenges the traditional OCR pipeline, and why the future of document AI might be *vectorless* and *vision-based*.
# 📑 Introduction to PageIndex
Are you frustrated with vector database retrieval accuracy for long professional documents? Traditional vector-based RAG relies on semantic *similarity* rather than true *relevance*. But **similarity ≠ relevance** — what we truly need in retrieval is **relevance**, and that requires **reasoning**. When working with professional documents that demand domain expertise and multi-step reasoning, similarity search often falls short.
Inspired by AlphaGo, we propose **[PageIndex](https://vectify.ai/pageindex)** — a **_vectorless_**, **reasoning-based RAG** system that builds a *hierarchical tree index* for long documents and *reasons* over that index for *retrieval*. It simulates how **human experts** navigate and extract knowledge from complex documents through **tree search**, enabling LLMs to *think* and *reason* their way to the most relevant document sections. It performs retrieval in two steps:
1. Generate a "Table-of-Contents" **tree structure index** of documents
2. Perform reasoning-based retrieval through **tree search**
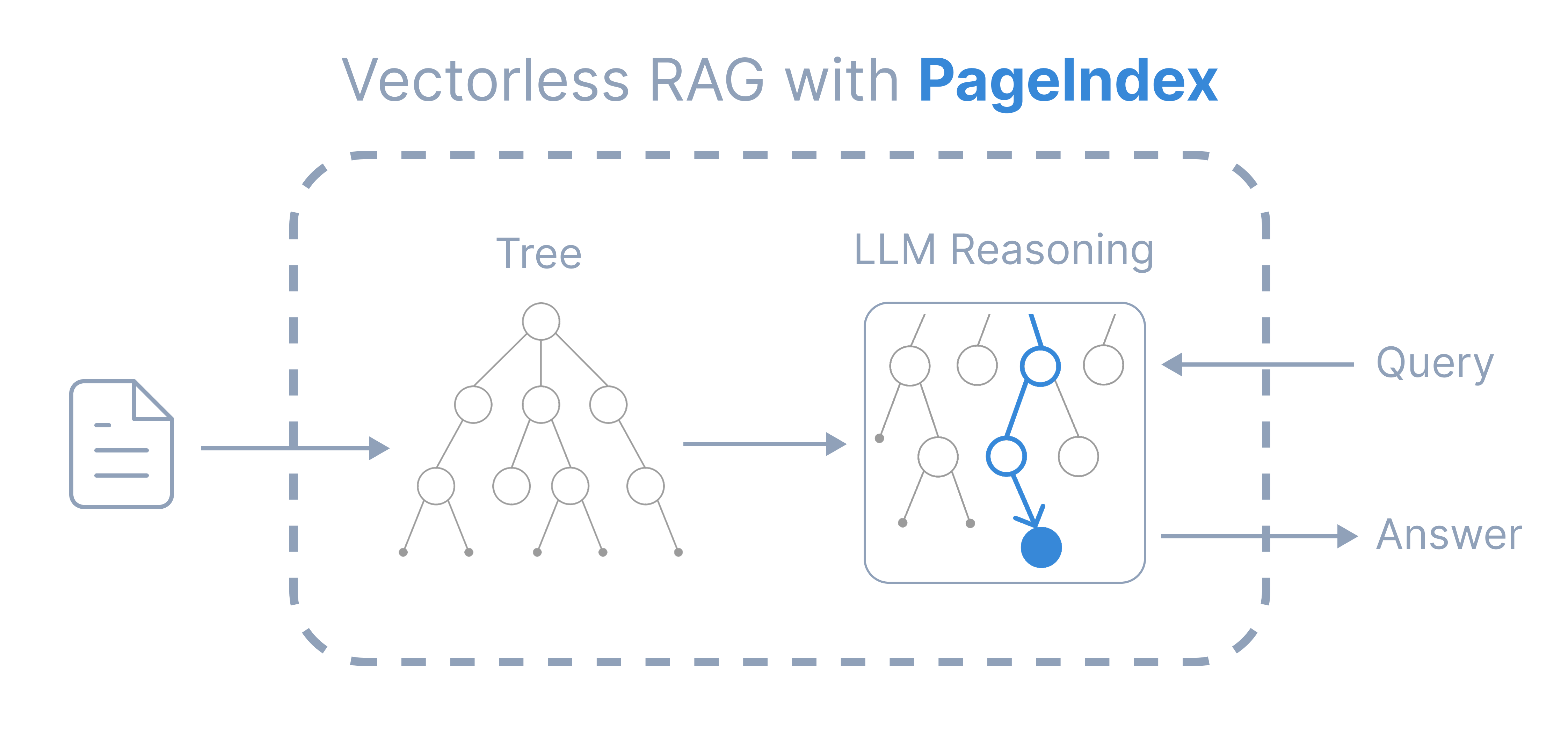
### 🧩 Features
Compared to traditional *vector-based RAG*, **PageIndex** features:
- **No Vector DB**: Uses document structure and LLM reasoning for retrieval, instead of vector search.
- **No Chunking**: Documents are organized into natural sections, not artificial chunks.
- **Human-like Retrieval**: Simulates how human experts navigate and extract knowledge from complex documents.
- **Transparent Retrieval Process**: Retrieval based on reasoning — traceable and interpretable. Say goodbye to approximate vector search ("vibe retrieval").
PageIndex powers a reasoning-based RAG system that achieved [98.7% accuracy](https://github.com/VectifyAI/Mafin2.5-FinanceBench) on FinanceBench, demonstrating **state-of-the-art** performance in professional document analysis (see our [blog post](https://vectify.ai/blog/Mafin2.5) for details).
### ⚙️ Deployment Options
- 🛠️ Self-host — run locally with this open-source repo.
- ☁️ **Cloud Service** — try instantly with our 🖥️ [Platform](https://chat.pageindex.ai/), 🔌 [MCP](https://pageindex.ai/mcp) or 📚 [API](https://docs.pageindex.ai/quickstart).
### 🧪 Quick Hands-on
- Try the [_**Vectorless RAG Notebook**_](https://github.com/VectifyAI/PageIndex/blob/main/cookbook/pageindex_RAG_simple.ipynb) — a *minimal*, hands-on example of reasoning-based RAG using **PageIndex**.
- Experiment with the [*Vision-based Vectorless RAG*](https://github.com/VectifyAI/PageIndex/blob/main/cookbook/vision_RAG_pageindex.ipynb) — no OCR; a minimal, reasoning-native RAG pipeline that works directly over page images.


---
# 🌲 PageIndex Tree Structure
PageIndex can transform lengthy PDF documents into a semantic **tree structure**, similar to a _"table of contents"_ but optimized for use with Large Language Models (LLMs). It's ideal for: financial reports, regulatory filings, academic textbooks, legal or technical manuals, and any document that exceeds LLM context limits.
Here is an example output. See more [example documents](https://github.com/VectifyAI/PageIndex/tree/main/tests/pdfs) and [generated trees](https://github.com/VectifyAI/PageIndex/tree/main/tests/results).
```jsonc
...
{
"title": "Financial Stability",
"node_id": "0006",
"start_index": 21,
"end_index": 22,
"summary": "The Federal Reserve ...",
"nodes": [
{
"title": "Monitoring Financial Vulnerabilities",
"node_id": "0007",
"start_index": 22,
"end_index": 28,
"summary": "The Federal Reserve's monitoring ..."
},
{
"title": "Domestic and International Cooperation and Coordination",
"node_id": "0008",
"start_index": 28,
"end_index": 31,
"summary": "In 2023, the Federal Reserve collaborated ..."
}
]
}
...
```
You can either generate the PageIndex tree structure with this open-source repo, or try our [API](https://docs.pageindex.ai/quickstart) service.
---
# 📦 Package Usage
You can follow these steps to generate a PageIndex tree from a PDF document.
### 1. Install dependencies
```bash
pip3 install --upgrade -r requirements.txt
```
### 2. Set your OpenAI API key
Create a `.env` file in the root directory and add your API key:
```bash
CHATGPT_API_KEY=your_openai_key_here
```
### 3. Run PageIndex on your PDF
```bash
python3 run_pageindex.py --pdf_path /path/to/your/document.pdf
```
Optional parameters
You can customize the processing with additional optional arguments:
```
--model OpenAI model to use (default: gpt-4o-2024-11-20)
--toc-check-pages Pages to check for table of contents (default: 20)
--max-pages-per-node Max pages per node (default: 10)
--max-tokens-per-node Max tokens per node (default: 20000)
--if-add-node-id Add node ID (yes/no, default: yes)
--if-add-node-summary Add node summary (yes/no, default: yes)
--if-add-doc-description Add doc description (yes/no, default: yes)
```
Markdown support
We also provide a markdown support for PageIndex. You can use the `-md_path` flag to generate a tree structure for a markdown file.
```bash
python3 run_pageindex.py --md_path /path/to/your/document.md
```
> Notice: in this function, we use "#" to determine node heading and their levels. For example, "##" is level 2, "###" is level 3, etc. Make sure your markdown file is formatted correctly. If your Markdown file was converted from a PDF or HTML, we don’t recommend using this function, since most existing conversion tools cannot preserve the original hierarchy. Instead, use our [PageIndex OCR](https://pageindex.ai/blog/ocr), which is designed to preserve the original hierarchy, to convert the PDF to a markdown file and then use this function.
---
# 📈 Case Study: SOTA on Finance QA Benchmark
[Mafin 2.5](https://vectify.ai/mafin) is a reasoning-based RAG system for financial document analysis, powered by **PageIndex**. It achieved a state-of-the-art [**98.7% accuracy**](https://vectify.ai/blog/Mafin2.5) on the [FinanceBench](https://arxiv.org/abs/2311.11944) benchmark — significantly outperforming traditional vector-based RAG systems.
PageIndex's hierarchical indexing enabled precise navigation and extraction of relevant content from complex financial reports, such as SEC filings and earnings disclosures.
👉 Explore the full [benchmark results](https://github.com/VectifyAI/Mafin2.5-FinanceBench) and our [blog post](https://vectify.ai/blog/Mafin2.5) for detailed comparisons and performance metrics.
---
# 🧭 Resources
* 📖 [Tutorials](https://docs.pageindex.ai/doc-search): practical guides and strategies, including *Document Search* and *Tree Search*.
* 🧪 [Cookbooks](https://docs.pageindex.ai/cookbook/vectorless-rag-pageindex): hands-on, runnable examples and advanced use cases.
* 📝 [Blog](https://pageindex.ai/blog): technical articles, research insights, and product updates
* ⚙️ [MCP setup](https://pageindex.ai/mcp#quick-setup) & [API docs](https://docs.pageindex.ai/quickstart): integration details and configuration options.
---
### ⭐ Support Us
Leave a star if you like our project. Thank you!

### Connect with Us
[](https://x.com/VectifyAI)
[](https://www.linkedin.com/company/vectify-ai/)
[](https://discord.com/invite/VuXuf29EUj)
[](https://ii2abc2jejf.typeform.com/to/tK3AXl8T)
---
© 2025 [Vectify AI](https://vectify.ai)